


How we revived and made our web-app snappy with help from Mafiree
A good friend recently asked me why there were no updates on Tinkerbee, especially on social media? The simple and honest answer is that we were either building, shipping, dealing with logistic challenges, trying to catch up on compliance stuff or firefighting some issue. The last two years, we have not done anything ‘new’. Two years ago, our theme was ‘survive’ and a year ago, it was to grow with whatever we had. Not a lofty BHAG, just a modest sustenance based anti-pattern.
Our journey has been fueled by the hope and kindness of many people (I aspire to create enough value for each of them as soon as I can). This post is a mark of gratitude to one such person/ team who helped us when our chips were down.
What our platform does
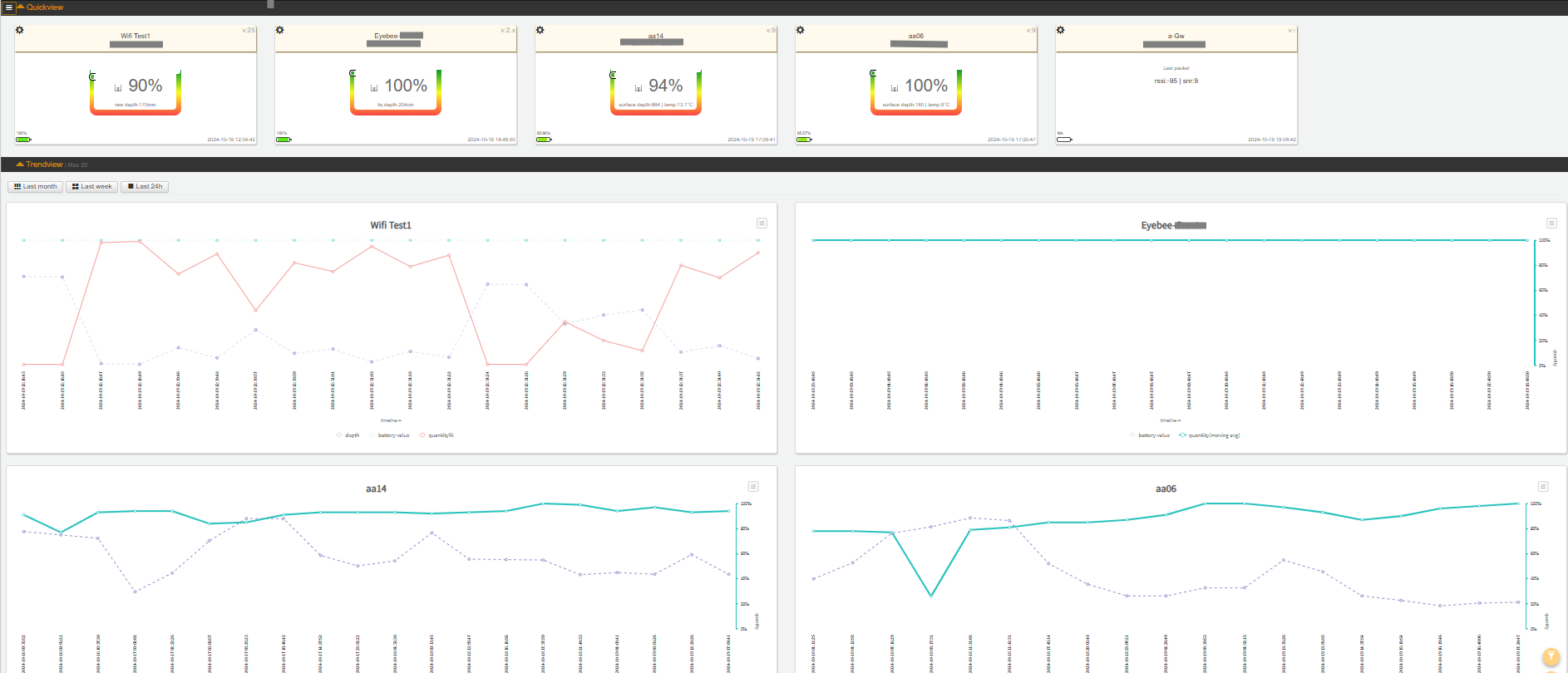
As you might know, we make/ use wireless sensors to read data and relay them to our online platform. We call this platform Beehive and the visualization front-end is called SenseSight.
The following diagram shows what Beehive does:

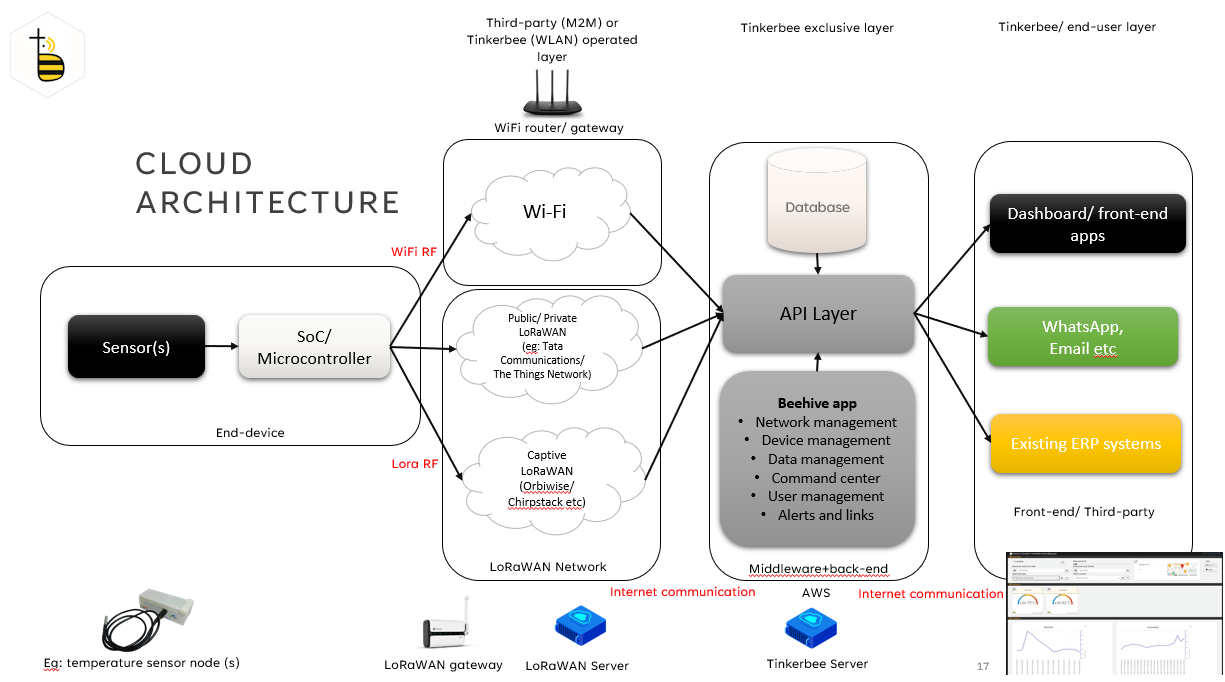
The platform continually ingests data coming from a few hundred sensors over multiple wireless networks, parses them based on a complex set of data unpacking rules (binary, json, pipe separated etc) and decryption (where applicable), particular to each device class and stores the incoming data. It also checks for rules related to alerts and linked devices (eg: when water level reaches x, turn on a water pump), handles appropriate downlinks and commands queued to devices and communicates with the appropriate network servers as well.
The visualization layer is a dashboard that shows a visual snapshot of the latest update from each device along with a graphical representation of historical data. Of course, there are reports, device manager, location manager, WhatsApp integration layer and Webhooks to integrate to any other third-party platform as well.
Now all this was essentially a LAMP stack app (Linux, Apache, MySQL and PHP). It was a monolithic single machine app (yikes) with a db replication instance (which was not syncing well) and an option of load-balancing. Yes, I can see many of you rolling your eyes. Well, the aim was to get something functional and fast and economical, based on my limited skills and it did the job well for a while. The platform handled just over 5 million sensor data packs, about 500 active sensors and about a dozen active users daily.
When things went ‘south’
All was well, until a month ago when the platform just could not handle things gracefully. We could throw more CPUs and RAM at it and fix things for a short while, but there were some fundamental issues. Page loads were taking about 15 to 20 seconds and map interface sometimes took about a minute to load! CPU usage was shooting dramatically to 100% in short bursts and AWS throttled further. Had to go through a couple of system reboots just to keep the machine chugging. I had planned some simple, but fundamental changes to the architecture but did not have the time and expertise to pull it off. Well, now something had to be done and done soon.
When sh!t hits the fan, you ask for help. You literally need to call in the specialists. I had known Mafiree and Chandru through my previous stint at Eko. Mafiree had proven their MySQL chops and had been our lifesavers in its early days and I believe was their managed database partner for a long time. So, I promptly reached out to Chandru and explained the situation to him. He promptly got his team to connect and was kind enough to offer a package that we could afford. I would like to express my gratitude to him and his team for their timely help.
The revival plan
The plan was as follows:
Stage 1
- Spin up 2 new Ubuntu VMs with only MySQL running (Mafiree)
- Set up both as slave instances first and sync to the existing master (Mafiree)
- Change application framework to separate reads and writes (Tinkerbee)
- Direct most of the reads to the new slave instance (Tinkerbee)
- Ensure full sync and data integrity and db-tuning (Mafiree)
- Switch the application to the new DB instances (Tinkerbee)
- Stop existing DB instance
Stage 2
- Move application Apache to NGINX (Mafiree)
- Ensure all modules and CLI cron jobs are also migrated (Tinkerbee)
- Ensure logging mechanisms are set up (Tinkerbee)
- Ensure Apache .htaccess rules are migrated to NGINX (Tinkerbee)
- Point DNS entries and certificates to the new app instance (few minutes downtime, Tinkerbee)
- Retire the old VMs
- Monitor and confirm all application and functionality is restored
The results
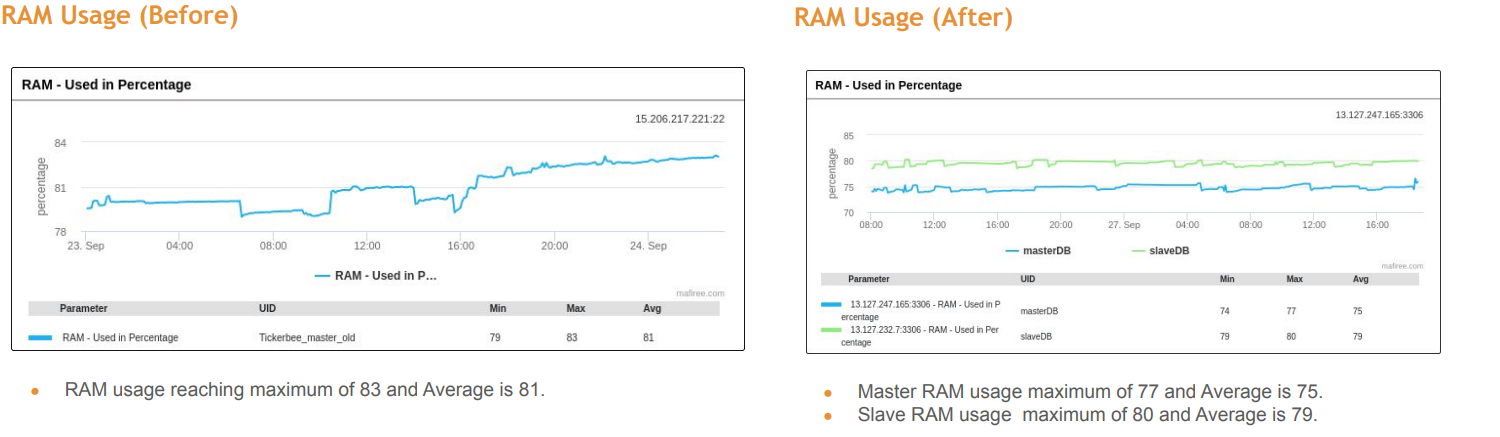
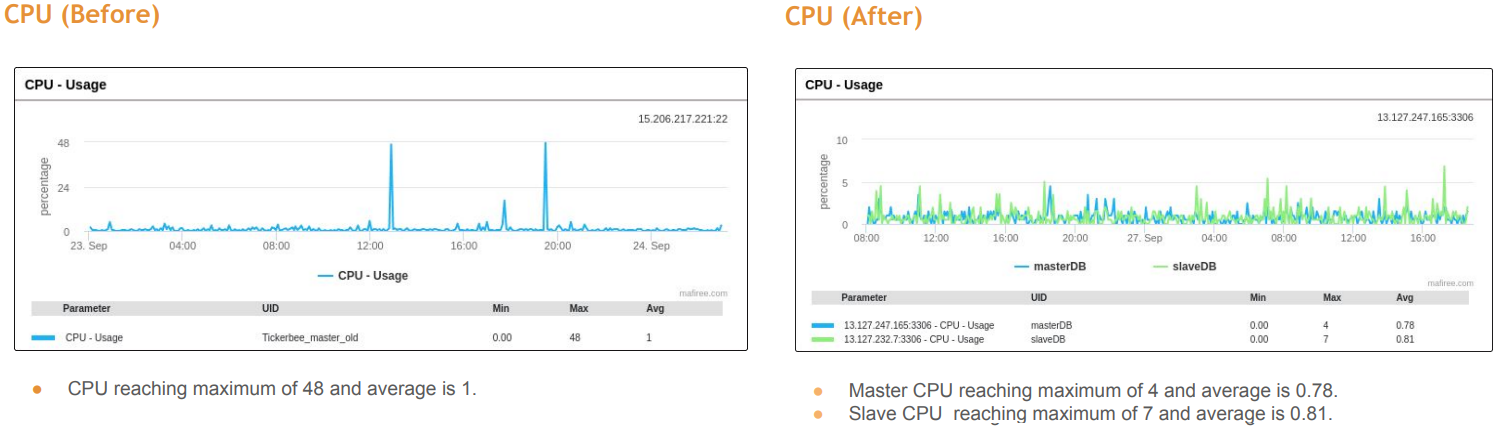
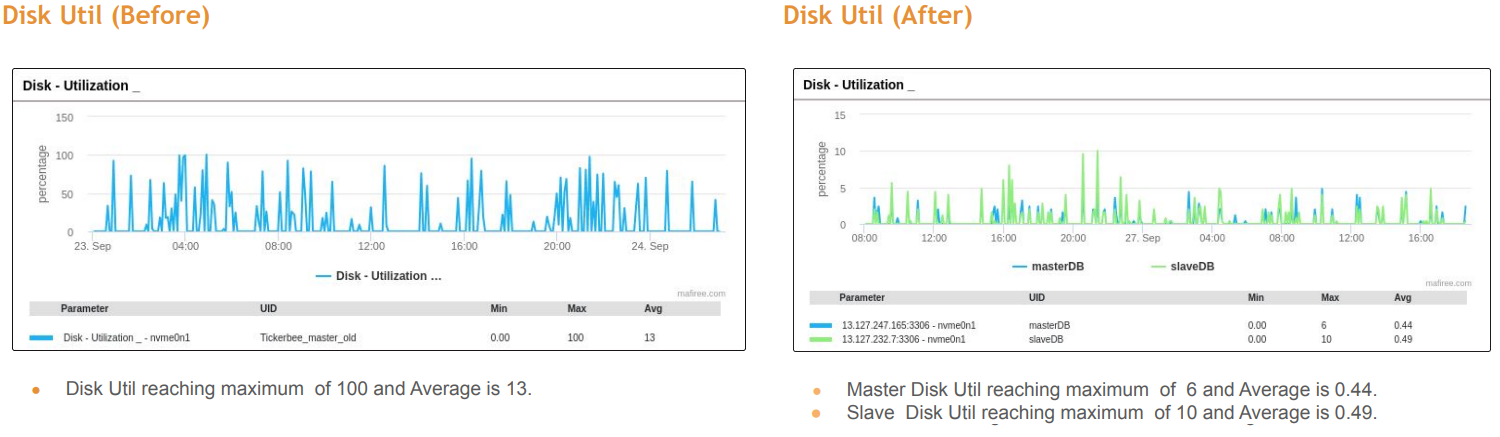
For the techies out there, the following before and after stats (from Mafiree’s post-implementation presentation) will give you a sense of what we achieved in about a week’s time of planning and execution with a downtime of less than a few minutes.

Conclusion
The following are the end-results:
- Elimination of all slow queries.
- Our application is now snappy 🙂
- Our customers are happy 🙂
- CPU usage decreased by over 90%
- RAM and disk utilization improved significantly, reducing load
- Our WiFi devices can now update data within 10 ms including decryption
- LoRaWAN network servers have reported between 20 and 30 ms
- Page load time is about 1.5 s with map interface, about 5 s
- Data auto-refresh less than 1 s
Once again a huge shout-out to team Mafiree for all their help. Thanks to all our partners and early-customers for all their support.
As always, do reach out to us via email, info at tinkerbee dot in (for any general/ product related queries) or anupam at tinkerbee dot in (for any specific or technical queries) to discuss how we might help you #maximizeYourLife


